LLM WebUI on Amazon Linux 2 (x86-64) with support by Hfami
AWS-Marketplace
https://aws.amazon.com/marketplace/pp/prodview-uos44e3g7b6s6
Usage Instructions
1.Activate the conda environment
conda activate textgen
2.Downloading large models
Hugging Face https://huggingface.co/
1.First, ensure you have a Hugging Face account.
2.After logging into your Hugging Face account, visit the page for Meta's Llama 3 model.
On the model page, select the version of Llama 3 you wish to apply for.
3.Find the application form and fill in the necessary information, including your country of application, email address, and other relevant details.
4.Submit the application and wait for the review process.
Once your application is approved, you will be able to download the Llama 3 model.
5.Second, create the token.
The interface for creating the token is shown in the following figure:
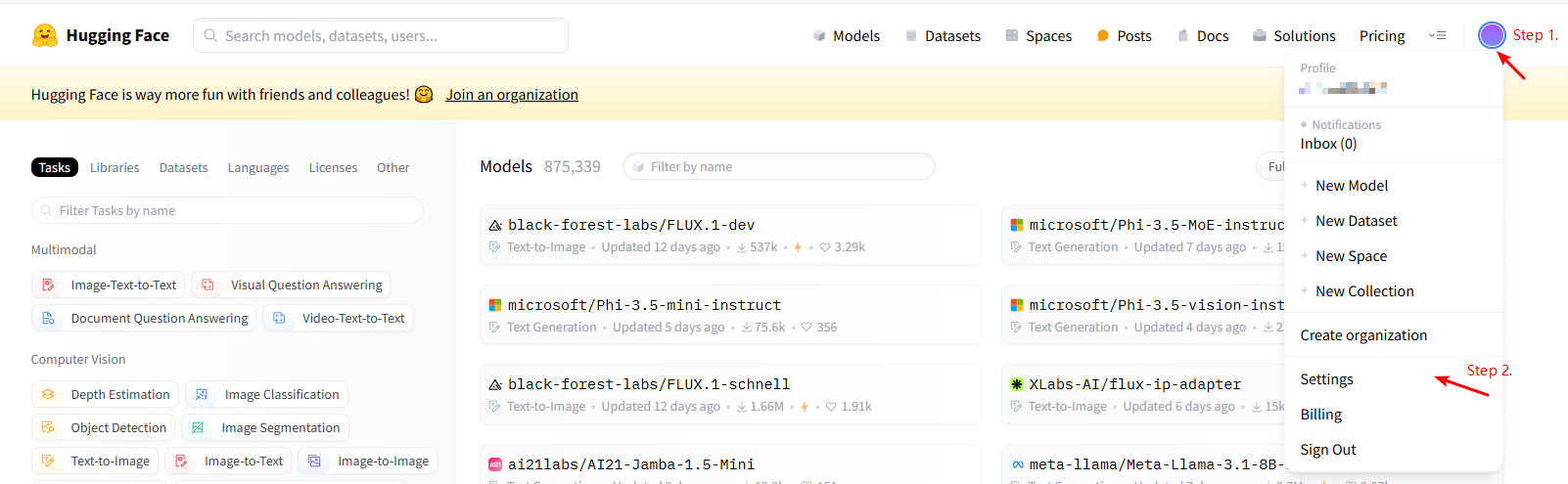
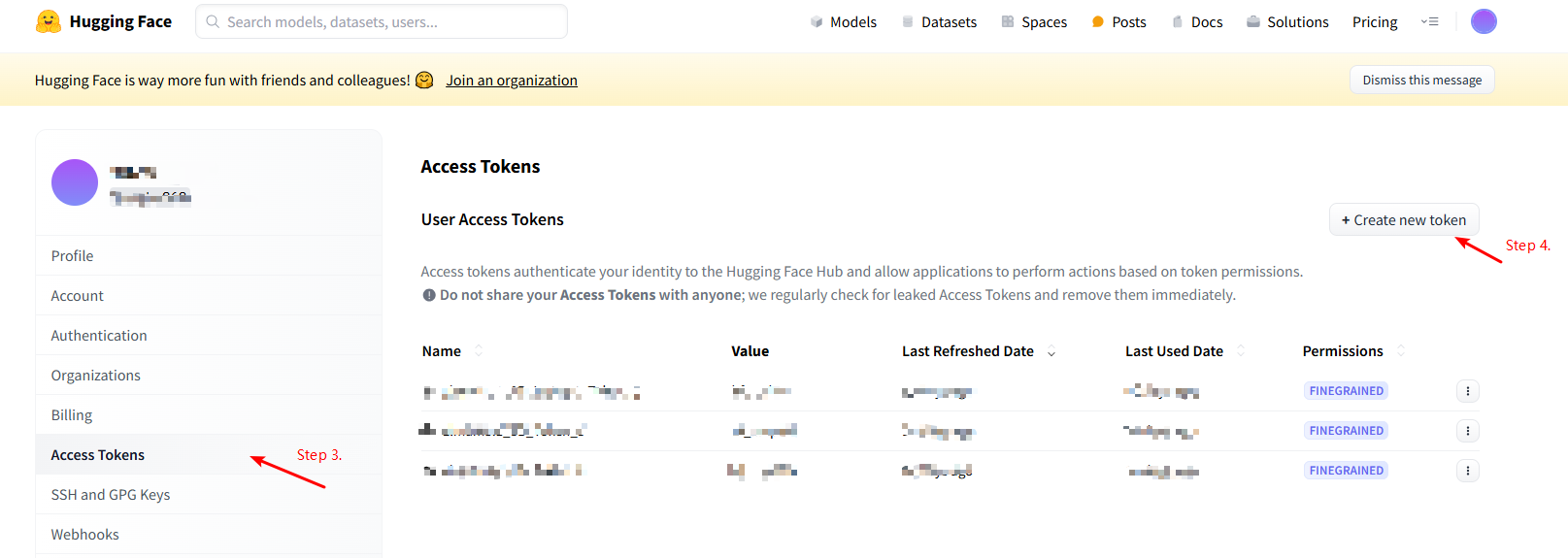
6.Log into huggingface from the command line:
huggingface-cli login
Login requires an account and token
Hugging Face compatible format
Put the full version of Meta-lema-3.1-8b-instruct in the models folder of text-generation-webui as follows:
text-generation-webui
└── models
└── Meta-Llama-3.1-8B-Instruct
├── config.json
├── generation_config.json
├── model-00001-of-00004.safetensors
├── model-00002-of-00004.safetensors
├── model-00003-of-00004.safetensors
├── model-00004-of-00004.safetensors
├── model.safetensors.index.json
├── special_tokens_map.json
├── tokenizer_config.json
└── tokenizer.json
Download file command:
- huggingface-cli download meta-llama/Meta-Llama-3.1-8B-Instruct --include "model-00001-of-00004.safetensors" "model-00002-of-00004.safetensors" "model-00003-of-00004.safetensors" "model-00004-of-00004.safetensors" "config.json" "generation_config.json" "model.safetensors.index.json" "special_tokens_map.json" "tokenizer.json" "tokenizer_config.json" --local-dir Meta-Llama-3.1-8B-Instruct
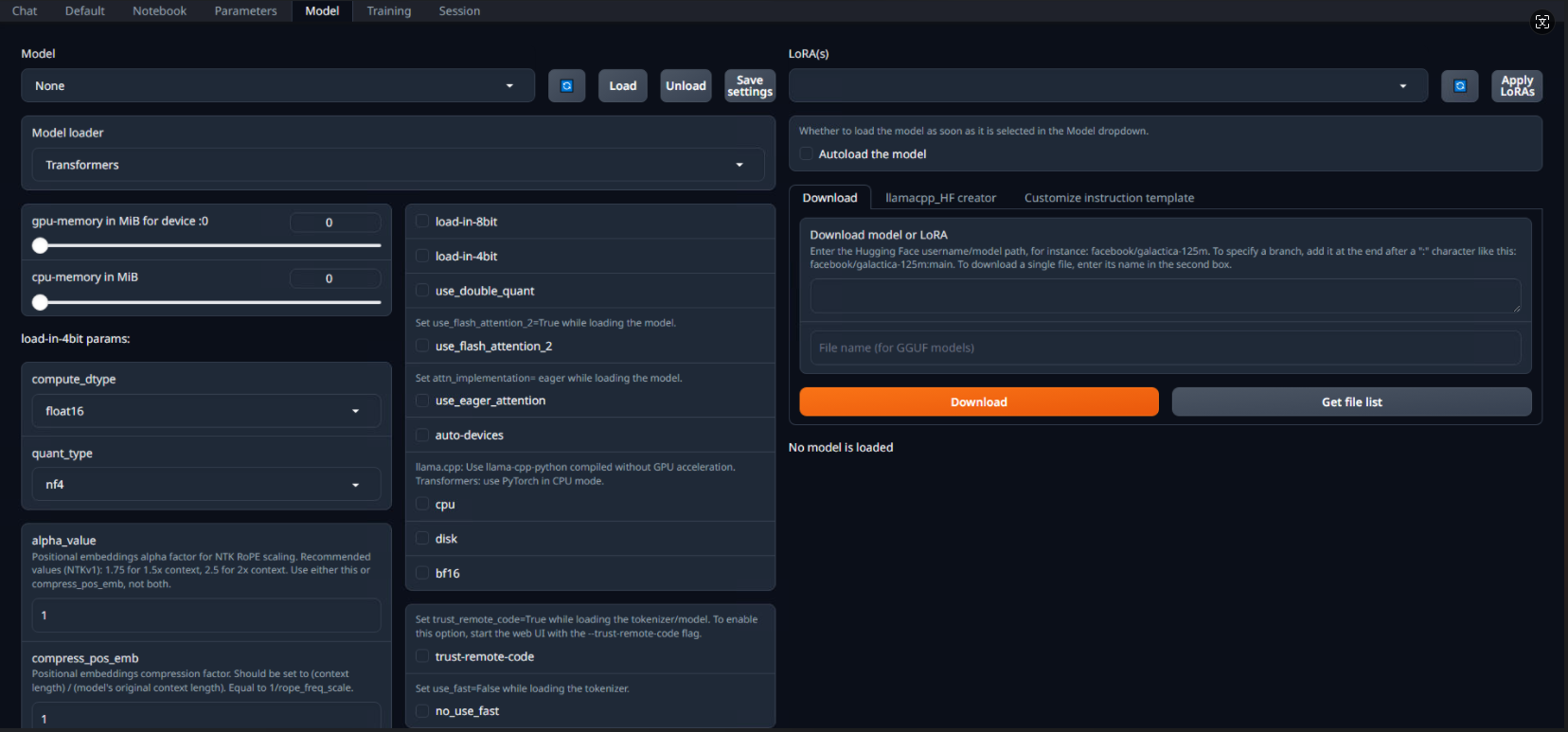
3.Load the model and configuration
python server.py --listen

You can access the web interface by visiting http://{public-ip}:7860 in your browser.
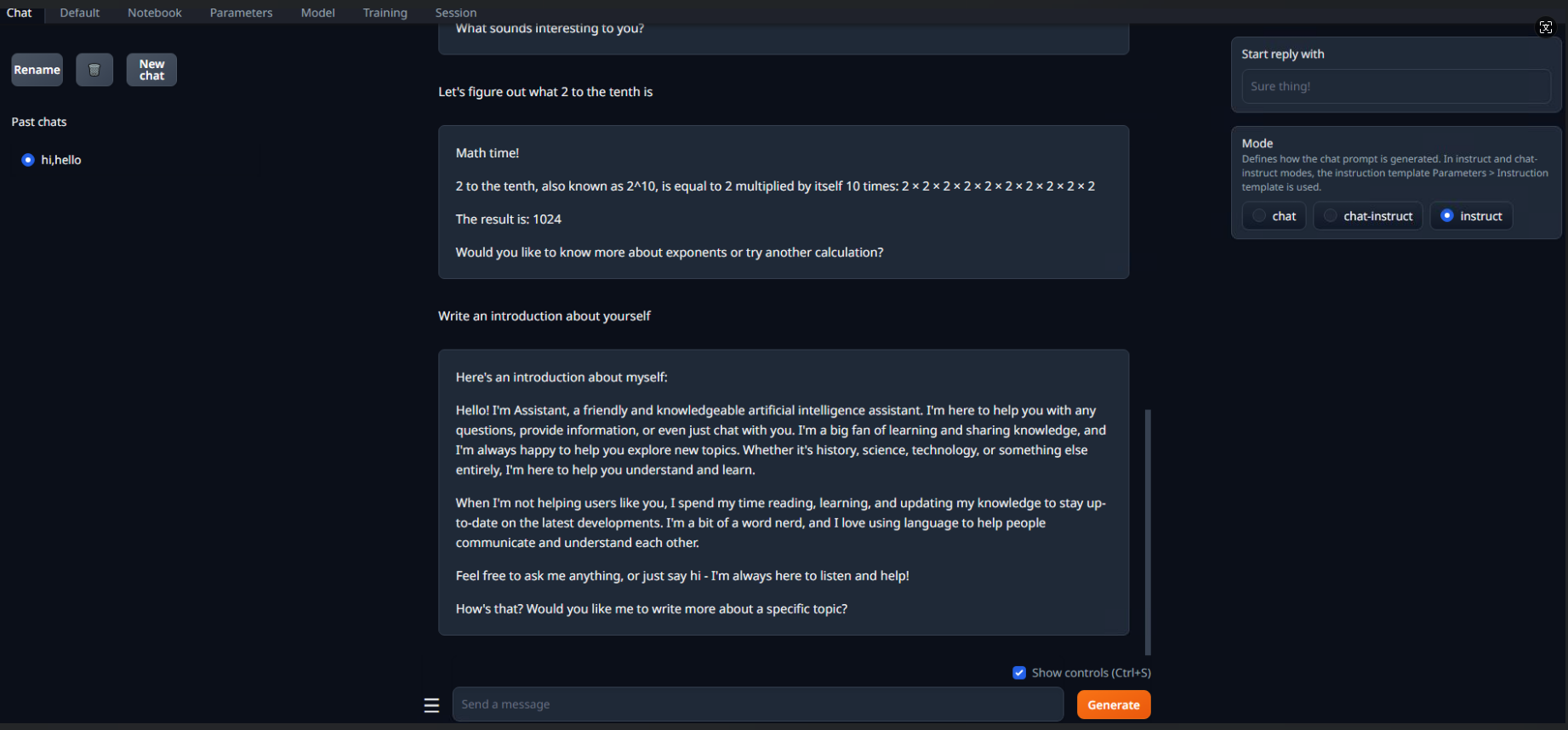
The interface looks like this:

Next up is some configuration:
1) Select the model TAB, select Meta-Llama-3.1-8B-Instruct from the drop-down list, and then click the load button to load the model.
2) Select the parameters TAB, and then select the instruction Template TAB. The instruction template looks like this:
{% set loop_messages = messages %}{% for message in loop_messages %}{% set content = '<|start_header_id|>' + message['role'] + '<|end_header_id|>
'+ message['content'] | trim + '<|eot_id|>' %}{% if loop.index0 == 0 %}{% set content = '<|begin_of_text|>' + content %}{% endif %}{{ content }}{% endfor %}{{ '<|start_header_id|>assistant<|end_header_id|>
' }}
4.Start a chat
Go back to the chat TAB and select "Instruct" from the Mode on the right to start a conversation with the model.
For more detailed usage, please explore the web interface or refer to the official manual. If you encounter installation or operation problems, please go to the original repo to search for solutions or ask questions.
5.Conda related commands:
- `conda info --envs`